


Biomedical Informatics and Smart Healthcare
ISSN: request pending (Online) | ISSN: request pending (Print)
Email: [email protected]

Artificial Intelligence (AI) is the field of science and technology focused on creating smart computer systems. These systems can perform tasks that typically require human intelligence and operate autonomously without constant human intervention [1, 2, 3]. These systems combine advanced algorithms, decision-making capabilities, and large datasets to generate insights and respond effectively to queries. Today, AI-powered technologies assist us in various aspects of our daily lives, with innovations such as autonomous vehicles, advancements in healthcare research, and wearable personal technology showcasing the immense potential of AI [4]. Healthcare is a sector where AI has a transformative impact, offering solutions that improve patient outcomes [5, 6]. AI assists healthcare professionals in making medical decisions, enhancing diagnostic accuracy, and personalizing treatment. AI can detect early indicators of Alzheimer's disease, facilitate comparative brain scan analysis, and provide diagnostic support in cardiology and radiology [7]. AI is also extensively used to detect abnormalities in medical scans, conduct complex genetic sequencing [8], and develop tailored treatment plans [9]. In ICUs, AI could completely change patient care and optimize resource management by accurately predicting patient LOS [10].
During the COVID-19 pandemic crisis, the efficient management of ICUs plays a crucial role. ICUs are often overwhelmed, leading to shortages of beds, medical equipment, and healthcare staff. This article highlights the use of artificial intelligence to predict and optimize ICU resource allocation, based on machine learning models capable of quickly identifying the most vulnerable patients who are likely to require intensive care. This approach not only enables better distribution of limited resources but also helps anticipate future needs based on clinical and demographic data, thereby reducing hospital overload and improving clinical outcomes. By integrating AI into decision-making, the study offers innovative solutions to address healthcare emergencies and paves the way for similar applications in other critical fields [25, 26].
The proposed hybrid AI model leverages diverse patient data to identify complex patterns and make reliable LOS predictions. This can make resources easier to use, help patients move through the system more smoothly, and lead to people being healthier while spending less money on healthcare. AI systems can guess which patients are most likely to get very sick, allowing doctors to act quickly and give improved, safer treatment. The remainder of this paper is organized as follows. Section 2 discusses the related scientific work of this study. Section 3 presents the proposed solution. Section 4 presents and discusses the results. Finally, Section 5 concludes the paper and outlines future work.
ICU doctors care for critically ill patients with complex conditions who often need life-saving treatments. With the growing demand for ICU care, making quick and effective decisions is more important than ever [11, 12]. Clinical decision-making is becoming more challenging due to the overwhelming amount of data, the growing number of diagnostic and treatment options, and the increasing complexity of patient care [13, 14, 15, 16]. Treatment protocols are designed to help doctors make decisions, but they often oversimplify real-life cases, which can be much more complex. While more data should, in theory, offer better insights, ICU doctors already struggle to process the massive amounts of clinical information available. In many cases, this data doesn't seem immediately useful for decision-making [17]. For instance, when treating patients on ventilators, ICU doctors may have to analyze over two hundred different factors [18]. ICU doctors are skilled at analyzing clinical data in the moment to make the best treatment decisions, but even the most experienced among them cannot continuously process the vast amount of information available [17]. Over the past decade, the medical field has seen the rise of AI and machine learning (ML) technologies, which have the ability to greatly enhance healthcare practices. ML, a branch of AI, focuses on how computers can learn from data without being explicitly programmed. These systems do not adhere to fixed rules but instead continuously learn and enhance their abilities through example analysis [27, 28]. Machine learning and AI perform vital functions in the ICU by processing vast clinical datasets to detect patterns while generating individual patient predictions. In the ICU setting the length of stay serves as a vital metric that reveals how long critically ill patients need specialized care from when they enter until they are released [29, 30]. Multiple factors influence ICU stay duration including illness severity along with additional health problems and potential complications. Healthcare providers benefit from AI and ML models that detect data patterns that lead to extended ICU stays including complication signs or condition deterioration thus enabling clinicians to make more precise patient outcome forecasts. Patients who need advanced life support systems or who experience multiple organ failures tend to have extended stays in the ICU. Through ongoing analysis of patient data AI models enable clinicians to predict complications including hospital-acquired infections and respiratory distress which typically result in prolonged hospital stays. Predictive capabilities enable healthcare providers to customize treatment plans and allocate resources efficiently leading to better patient care. Treatment efficiency and ICU patient stay duration depend on access to specialized equipment, staff expertise levels and the effectiveness of care coordination. An AI system can allocate medical resources by forecasting ICU bed availability and by optimizing the timing of medical interventions.
Despite significant progress in predicting Length of Stay (LoS) in intensive care units, existing studies still face several key limitations, as shown in Table 1, excessive simplification through binary classification, reliance on highly complex data, and heterogeneous performance across patient subpopulations. These issues limit the clinical utility, generalizability, and interpretability of the models. In this context, we propose an innovative hybrid model that combines feature selection using Random Forest with prediction through a Deep Neural Network (DNN).
| Contribution | Task | Model / Method | Limitations |
|---|---|---|---|
| [35] | Classification: short vs. long ICU stay | Random Forest | Single-center data; no continuous regression of LoS |
| [36] | Continuous regression: direct prediction of length of stay | Multi-scale 1D Convolutional Neural Network (1D-MSNet) | High computational cost; requires dense time-series vital signs |
| [37] | Continuous regression: prediction of hospital LoS (incl. ICU) | Tree-based regression (CatBoost for non-newborns; linear regression for newborns) | Large-scale administrative data; performance varies by group (newborn vs. non-newborn) |
Our approach aims to balance performance, explainability, and clinical applicability, effectively addressing the shortcomings observed in current methods.
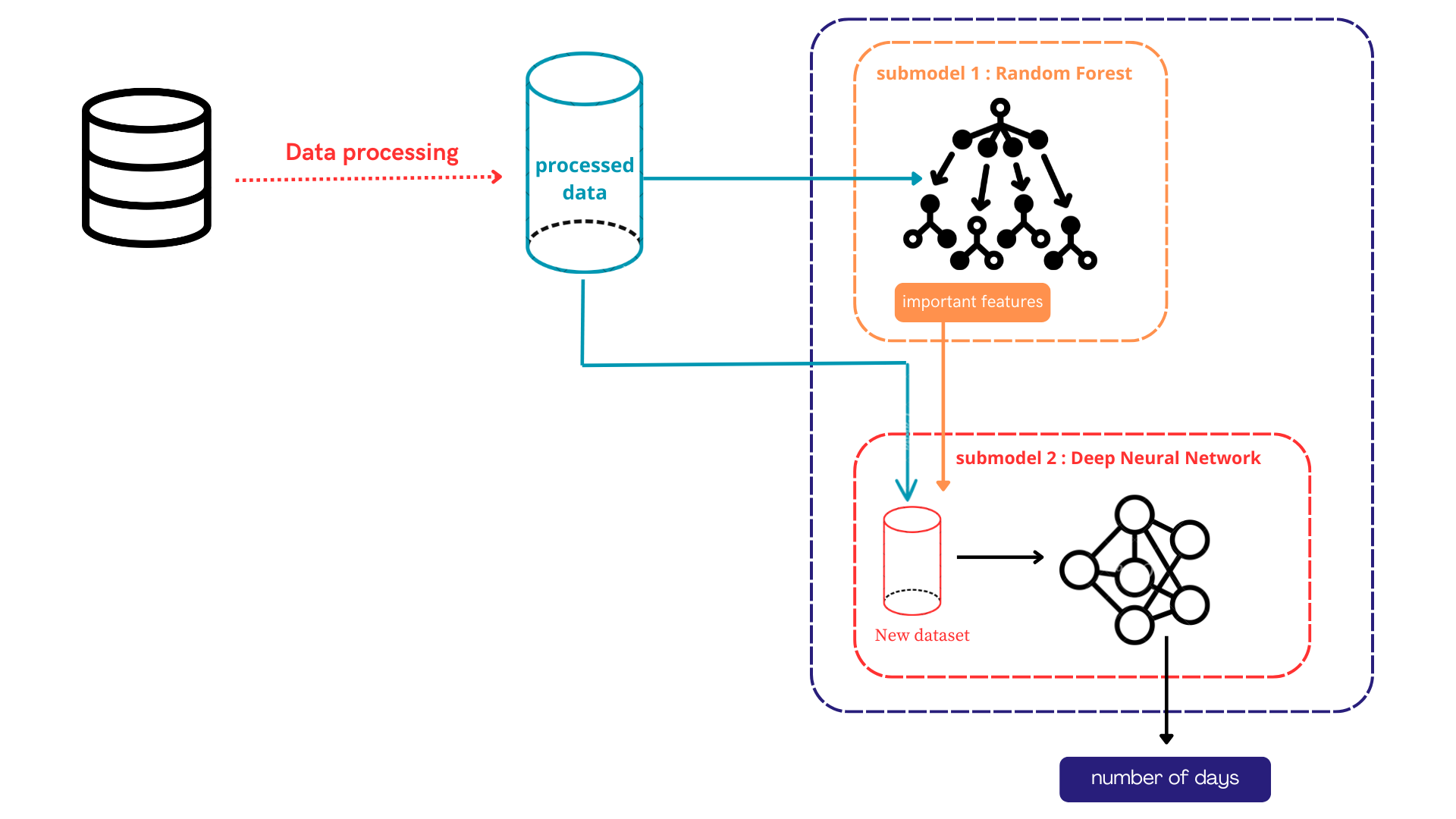
As stated before, this research will concentrate on two main goals: finding the most important features and picking the right model to guess how long a patient will stay in the ICU. These goals are very important for creating a correct and dependable prediction model that can help doctors make important decisions. In short, our combined model uses two strong machine learning methods: Random Forest (RF) and Deep Neural Networks (DNN), as seen in Figure 1. First, the RF model finds the most important features in the data. After the key features are chosen, the DNN, a sophisticated deep learning tool, is used on the simplified data to make very accurate guesses about how long the patient will likely stay in the ICU. By combining these two approaches: RF to select the important feature and DNN for prediction, our hybrid model uses the good parts of two different ways of doing things. This smooth connection helps us create a solid and trustworthy system for guessing how long people will stay in the ICU. This is very important for making better patient care plans, using resources wisely, and making the whole healthcare system work better.
The hybrid nature of our model also allows for greater flexibility and adaptability. As new data is collected or patterns change over time, the RF component can be updated to focus on the most important features, while the DNN can be adjusted or fully retrained to maintain the accuracy and relevance of the predictions. This dynamic and iterative approach ensures that our model remains at the forefront of patient outcome forecasting, providing healthcare professionals with the insights they need to make informed decisions and deliver the best possible care.
One of the key strengths of our proposed solution lies in the initial phase of our hybrid model, which leverages the Random Forest algorithm. This phase is designed to uncover the underlying relationships between features and to automatically identify the most relevant variables for the prediction task. As a result, our model is particularly robust and versatile, capable of being applied to a wide range of datasets with varying feature sets. The Random Forest component serves as an intelligent feature selection mechanism, isolating the most informative attributes that are then used to predict the number of days a patient is likely to spend in the Intensive Care Unit (ICU). Consequently, the early stage of our system—data processing—can focus primarily on preparing raw data for analysis by ensuring that it is clean, consistent, and properly formatted for input into the hybrid model.
In our context, the data processing phase comprises several essential steps, including data cleaning, normalization and scaling, and the encoding of categorical variables such as gender or diagnosis codes. These categorical features are transformed into numerical representations using techniques like one-hot encoding or label encoding. Finally, the dataset is split into training and testing subsets to allow for robust and unbiased model evaluation. Following data preprocessing, the workflow transitions into the hybrid modeling phase, which is composed of two sub-models. The first sub-model, based on the Random Forest algorithm, is responsible for selecting the most important features, as detailed in Section 3.1. Once the relevant features have been identified, the second sub-model—a Deep Neural Network (DNN)—is applied for the final prediction task, as described in Section 3.2. This structured approach not only streamlines the overall workflow but also enhances the generalizability and scalability of the system across diverse healthcare datasets.
Choosing the right features is very important for making good prediction models [31, 32]. When we pick and keep only the most important features, we get rid of useless or repeating information. This makes the model work better, easier to understand, and more accurate. It also saves time and effort when training and testing the model. Research shows that Random Forest (RF) works really well for this, better than methods like Correlation, PCA, and LDA. RF is a machine learning method that uses many decision trees and puts their predictions together by averaging (for predicting numbers) or voting (for putting things into groups). It figures out how important each feature is by seeing how much each feature helps in making better splits, or by mixing up the feature values and seeing how much worse the predictions get. RF is especially good for data that is complicated and has features that affect each other in non-obvious ways. What sets RF apart as a feature selection method is its versatility and robustness, especially when dealing with high-dimensional datasets containing many potential variables. It not only identifies the most informative features but also handles multicollinearity and non-linear dependencies effectively. By reducing the features, RF simplifies the model, takes less time to train, and boosts generalization since the chance of overfitting goes down. It also tackles the problem of "dimensionality curse"; this is when unnecessary or duplicate features make a model perform worse. Such advantages are what make RF great for feature selection in numerous domains, from healthcare to finance and beyond [19, 20]. To evaluate the model, we use Accuracy as a primary metric (Equation 1). Accuracy is the simple and typical performance metric computed as the percent of correct predictions of the model. It gives a straightforward, easy-to-understand indication of how well the model is performing. By calculating Accuracy, we measure the percent of correct instances in which the model's predictions align with these true, known labels or outcomes. Thus, it provides a clear and concise way to assess how successful the model is overall in making accurate predictions.
where:
To predict the number of days a patient will spend in the ICU, we have strategically chosen DNN as our modelling approach. This decision is grounded in their proven ability to capture and model complex, non-linear relationships within large and multidimensional datasets. Studies have shown that DNN outperform traditional ML methods in healthcare applications, particularly when dealing with noisy, heterogeneous, and high-dimensional data [21, 22]. They excel at extracting meaningful patterns from intricate data structures, making them particularly suitable for scenarios where variable interactions and dependencies are highly nuanced, such as ICU length-of-stay predictions [23]. By harnessing their advanced pattern recognition and learning capabilities, we seek to develop a highly accurate and robust predictive model that provides clinicians with reliable insights into a patient's expected LOS in critical care. Such predictions can significantly contribute to optimizing resource allocation, enhancing patient outcomes, and supporting data-driven, informed decision-making across the healthcare system [24].
The DNN architecture used in our study consists of three fully connected hidden layers, each designed to capture complex, non-linear relationships within the data. All hidden layers utilize the ReLU activation function to introduce non-linearity and enhance learning capabilities. To mitigate the risk of overfitting and improve the model's generalization performance, dropout layers are applied after the first and third hidden layers. The final output layer comprises a single neuron with a linear activation function, specifically designed to predict the continuous target variable—ICU length of stay. To evaluate the performance of our second model, we utilized a comprehensive set of evaluation metrics to assess its accuracy and predictive capabilities. The first metric we employed was the Mean Absolute Error (MAE) (Equation 2), which measures the average absolute difference between the predicted values () and the actual target values (). This metric provides a clear view of the average size of the errors in the model's predictions, helping us assess its overall accuracy. MAE is defined as:
where:
: Number of observations,
: Actual value for the i-th observation,
: Predicted value for the i-th observation.
Along with the MAE, we also calculated the Mean Squared Error (MSE) for the second model, as shown in (Equation 3). The MSE considers the squared differences between predicted and actual values, giving more emphasis to larger errors. This metric helps us understand the overall variability in the model's predictions. MSE is defined as:
Finally, we evaluated the (Coefficient of Determination) (Equation 4) for the second model. This metric reflects the proportion of variance in the target variable that the model is able to explain. It is calculated as:
where denotes the mean of the actual values. The value ranges from 0 to 1, where a value of 1 means the model perfectly explains the variability in the target variable, and a value of 0 means the model provides no explanatory power.
We use a dataset comprising comprehensive clinical information that encompasses a wide range of data related to patients undergoing various surgical procedures. This includes detailed demographic information, such as age and gender. Additionally, the dataset captures extensive perioperative data, providing insights into patients' health status and conditions prior to surgery, including parameters such as vital signs. This dataset, which encompasses 70 distinct parameters across 6,388 surgical cases, serves as a rich and valuable resource for exploring the relationships between patient characteristics, surgical factors, and clinical outcomes. The dataset is openly accessible and can be downloaded from the PhysioNet platform. All data is securely stored in the public cloud after being anonymized to ensure privacy and compliance with ethical standards. According to our model, by following the process steps defined in Figure 1, we divided the implementation into three parts:
Pre-processing and Feature Definition: We began by pre-processing the dataset, defining, extracting, and encoding feature vectors and target labels. For the initial training, all features were used.
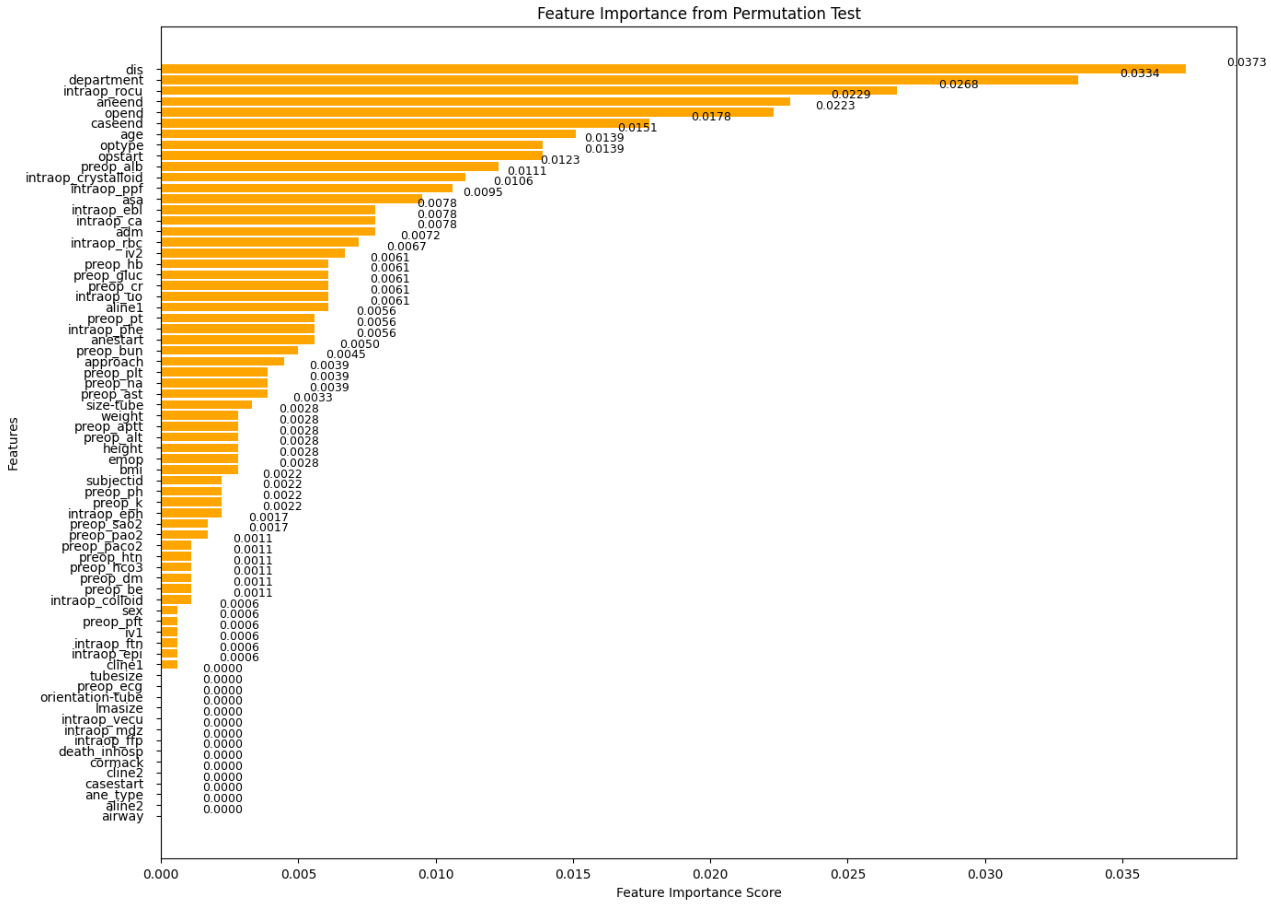
RF Model and Feature Selection: After preprocessing the data, we built our first model using an RF algorithm. We applied Permutation Feature Importance to identify the key features. The model achieved an accuracy of 93%, which is very satisfying.
As shown in Figure 2, the features are sorted by their calculated importance scores. We can eliminate the least important ones, specifically those with a score of 0 as shown in Figure 3.

DNN with Selected Features: Based on the feature selection process, we updated the dataset by retaining only the most important features in the global dataset. These features were then used as input variables for our DNN, this model produced the following results: MAE = 0.0033, MSE = 0.00012, and = 0.52501. Figure 4 presents a graph illustrating the difference between the true and predicted values for the number of days in the ICU across 200 test samples.
Our hybrid model integrates the Random Forest (RF) algorithm in the first stage for preliminary analysis and feature importance extraction. This initial phase yielded promising results, confirming the suitability of the RF methodology for identifying key predictors of ICU length of stay (LOS). However, it was not until the Deep Neural Network (DNN) was incorporated in the second stage that the core objective—accurate LOS prediction—was addressed, albeit with suboptimal initial performance. The DNN's limited predictive accuracy at first led us to further investigate potential causes such as suboptimal hyperparameter configurations, non-optimized network architecture, and imbalances within the dataset. These limitations are actively being addressed through iterative refinement, as we maintain strong confidence in the potential of this deep learning component to achieve improved performance.
Compared to existing approaches, our hybrid architecture shows competitive and even superior performance in terms of predictive accuracy. For instance, while our DNN achieved an of 0.525, traditional statistical models such as multivariate regression applied to intra-ICU variables [33] have reported lower values (e.g., 0.45), and large-scale multicentric models using stacking techniques [34] have reached up to 0.36. Furthermore, although these external models benefit from broader datasets and demonstrate applicability in real-world settings, they often lack the modularity and adaptability inherent in our hybrid design. Notably, our feature selection stage not only mitigates the curse of dimensionality but also enhances interpretability, a crucial factor for deployment in clinical environments.
In terms of ethical concerns, we emphasize the importance of data privacy. All datasets used in this study were strictly anonymized and handled in accordance with applicable ethical standards, and any future research will follow the same principles to ensure compliance with data protection regulations. Moreover, we recognize that predictive tools like ours—particularly those estimating ICU length of stay—may impact resource allocation and hospital management decisions. For this reason, it is imperative that such tools are used solely to assist and inform clinical decision-making rather than replace it. This safeguards vulnerable patient populations and mitigates the risk of indirect discrimination based on algorithmic outputs.
Overall, the modular structure of our hybrid system is a distinct advantage. It allows for flexible integration of future advancements in machine learning and deep learning, making the model both scalable and resilient to changes in data patterns. This adaptability, combined with ethical vigilance and ongoing optimization, positions our solution as a promising and responsible tool for supporting ICU resource planning and personalized patient care.
This research demonstrates the potential of hybrid AI models that combine ML and DL techniques to support clinical decision-making and improve patient care in ICUs. By accurately predicting the LOS of ICU patients using vital signs, the study introduces a novel approach that integrates RF and DNN. This hybrid method offers clear advantages in terms of resource allocation, patient flow optimization, and enhanced healthcare outcomes. Moreover, the study emphasizes the critical importance of model interpretability to facilitate the successful integration of AI technologies in clinical practice.
While our initial results are promising, we acknowledge the need for further improvements. As part of our future work, we plan to enhance the performance of our hybrid model and validate its generalizability by testing it on diverse real-world datasets. This includes evaluating the model under a variety of clinical conditions—ranging from typical to rare cases—to ensure its robustness and practical applicability. We believe that such efforts are essential to demonstrating the effectiveness of our approach and promoting its adoption in diverse healthcare environments.
 Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Biomedical Informatics and Smart Healthcare
ISSN: request pending (Online) | ISSN: request pending (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/