
Frontiers in Educational Innovation and Research
ISSN: request pending (Online)
Email: [email protected]

With the rapid development of information technology, technological breakthroughs in the fields of big data, cloud computing, artificial intelligence and other fields continue to emerge, which has brought about profound changes in all walks of life. In the field of operations research, mathematical modelling and optimization analysis methods play a crucial role in solving complex problems. Therefore, for mathematical formulas in operations research, we need to find it and distinguish it, and identify the named entities in the formulas accurately, which helps to improve the efficiency and accuracy of operations research.
Latex is a coding language for the representation of formulas in operations research, and it is also involved in other industries or professions related to mathematical formulas. Nonetheless, the topic of named entity recognition in operations research has seen comparatively little investigation and effort, and no sizeable and accessible datasets have been compiled. As a result, dealing with current problems in the field of formulas in operations research with existing techniques achieves mediocre results due to the lack of sufficient reference and experimental data.
Named Entity Recognition is a fundamental task for several natural language processing applications such as knowledge base question and answer systems, machine translation, information retrieval, sentiment analysis, and knowledge mapping. Finding specific entities, such as names of individuals, locations, organizations, etc. from a piece of text, and distinguish them from non-entities is the main objective of NER. Named entity recognition of latex texts makes further research possible. Accordingly, this paper constructs a dataset from the text of operations research courses in schools and related digital resources, and conducts research on entity recognition in operations research on the basis of the dataset.
This paper proposes a mathematical formula named entity recognition model consisting of BERT, BiLSTM and Transformer, for addressing the above issues. The BERT model is used to obtain the vector representation of each character, which is spliced with the vector representation of a randomly initialized instance query, and then jointly fed into BERT for encoding, and then the query semantics are enhanced by using One-Way Self-Attention so that the query can be modelled in terms of its connections with each other. This is followed by feature extraction through the BiLSTM layer and transformer layer, and finally the final predicted labelling results are obtained by finding the optimal allocation by finding the minimum cost matrix for the allocation problem.
The research progress in named entity recognition techniques can be divided into the following stages:
The first stage is the use of dictionary and rule based approach. Firstly, a candidate dictionary is obtained based on statistical analysis, and then manual screening is used while extracting the important terms in the domain. Using the a priori knowledge of the lexicon, potential entities in the sentence are matched, after which they are filtered according to rules. Rule-based approaches tend to rely too much on manually defined rules and templates, and thus may have limitations in their coverage for complex linguistic expressions and diverse inputs. Moreover, manually constructed rules are subjective and prone to bias and errors.
The second stage is the statistical machine learning based approach, in which researchers begin to try to use statistical models for named entity recognition. For instance, in a research finished by Yu et al. [1], they utilized Hidden Markov Model (HMM) for the recognition of Chinese named entities; Huang et al. [2] suggested an approach combining Support Vector Machine (SVM) with transformation-based error-driven learning for biological entity recognition; A named entity recognition technique based on conditional random fields was proposed by Feng et al. [3]. Statistical machine learning based methods no longer rely on hand-constructed tedious rules, however, they need a large number of training sets with clear labels, which still takes a lot of effort and resources.
The third stage is deep learning based named entity recognition. With the theory and application of deep learning gradually coming into people's attention, in addition to the improvement of algorithms and computer performance, the depth and width of neural networks [4] are also increasing. As a result, many neural network structures have emerged that are particularly well known today, the Convolutional Neural Network (CNN) [5], the Recurrent Neural Network (RNN) [6], the Long Short Term Memory Network (LSTM), and even more intricate deep learning models like BERT (Bidirectional Encoder Representation from Transformer) [7]. Deep learning models can learn and extract features from data on their own, in contrast to standard machine learning techniques that require feature extraction by hand. Deep learning greatly saves the human resources required for feature fusion, and deep learning models can automatically learn complex language patterns with strong generalization ability, which enables them to be better applied to practical tasks. For example, unidirectional Long Short Term Memory (LSTM) networks [8] are widely used in NER tasks due to their strong sequential feature extraction ability and are often combined with CRF (LSTM-CRF [9]) to achieve better recognition results. However, since unidirectional LSTM networks is limited to extracting unidirectional text features, Lample et al. [10] then proposed a Bidirectional LSTM (BiLSTM) network on this basis to obtain global contextual deep features, and then combined with CRF to form a BiLSTM-CRF neural network, it enhances the model's effect even further, and since then the model has gradually become the mainstream model for deep learning to solve NER problems in various fields. For example, Zhou et al. [11] promoted knowledge mining of ancient Chinese medicine books by extract text features using the BiLSTM-CRF method; Cheng et al. [12] applied the BiLSTM-CRF model to the field of ancient Chinese literature, and realized the processing tasks of automatic sentence breakage, automatic word division, lexical annotation and other processing tasks of the ancient Chinese information, and achieved very good results.
Meanwhile there are many scholars who have improved and innovated the BiLSTM-CRF model. For example, Huang et al. [13] introduced an external cybersecurity lexicon to enhance the features of cybersecurity texts based on the BiLSTM-CRF model, and obtained a favorable outcome on the cybersecurity dataset. On the field of agriculture, Zhou et al. [14] firstly processed the long text of the dataset into short text, and then input it into the ERNIE model for encoding to get this representation that preserves semantic associations, and subsequently enter it into BiLSTM-CRF to address the issues of low efficiency of the soil fertility named entity recognition method and poor text processing effect. Regarding the study of Chinese, Li et al. [15] introduced Hybrid Attention mechanism (Hybrid Attention) into BiLSTM-CRF model to achieve good semantic analysis ability and accurately represent the negation semantics in a sentence.
The Iterative Expanded Convolutional Neural Network (IDCNN), which can effectively extract local features across a wide acceptance domain, was also applied for Named Entity Recognition for the first time by Strubell et al. [16]. In order to solve the named entity identification issue in electronic medical records, Chen et al. [17] presented an attention mechanism based on the IDCNN-CRF model, and the special step-size of the inflated convolution can extract the text features more accurately with excellent recognition results.
To improve the word vectors' semantic representation, scholars have proposed pre-trained language models. Peters et al. [18] proposed ELMo model based on BiLSTM structure, which is able to extract bi-directional textual features. Radford et al. [19] proposed GPT (Generative Pre-trained Transformer) model, which is able to capture more distant semantic features.is able to capture more distant semantic information, but because it is a unidirectional model, it is unable to obtain global contextual information. Therefore, Devlin et al. [8] from Google team proposed the BERT model with bidirectional Transformer encoder structure. This boosts its performance on named entity recognition tests and further refines the semantic representation of word vectors. For example, Li et al. [20] utilized the BERT-CRF model to the joint extraction of maize breeding entity relationships, which provides an effective data base for the construction of maize breeding knowledge graph and other downstream tasks; Zheng et al. [21] utilized the BiLSTM-CRF model based on BERT for web content monitoring to identify sensitive words and variants, and the recognition effect is improved compared with other models; Yu et al. [22] proposed an ancient poetic place name recognition model, referred to as DABERT-CRF, using a data enhancement method while integrating BERT-CRF, as a way to promote further research on Chinese classical literature; Li et al. [23] used BERT and BiLSTM, combined with a bilinear attention mechanism, to successfully improve the semantic information and attain favorable outcomes in the Chinese recognition of medically named entities. Good results have been achieved on it.
The NER task was redefined as a machine-reading task in recent years by Luo et al. [24], Mengge et al. [25] and Zheng et al. [26], who demonstrated strong performance on both flat and nested datasets. With the goal to extract entities, they create type-specific queries based on external knowledge and treat phrases as contexts. They create PER-specific queries in natural language form, for instance, for the statement "U.S. President Donald Trump is enjoying his vacation in Miami" in order to extract PER entities like "U.S. President" and "Donald Trump". However, only one type of entity can be extracted for each inference because searches are type-specific. This approach overlooks the inherent relationships between different entity types in addition to producing ineffective predictions. Furthermore, Type-specific searches are manually constructed using external knowledge, which makes realistic scenarios using hundreds of entity types difficult.
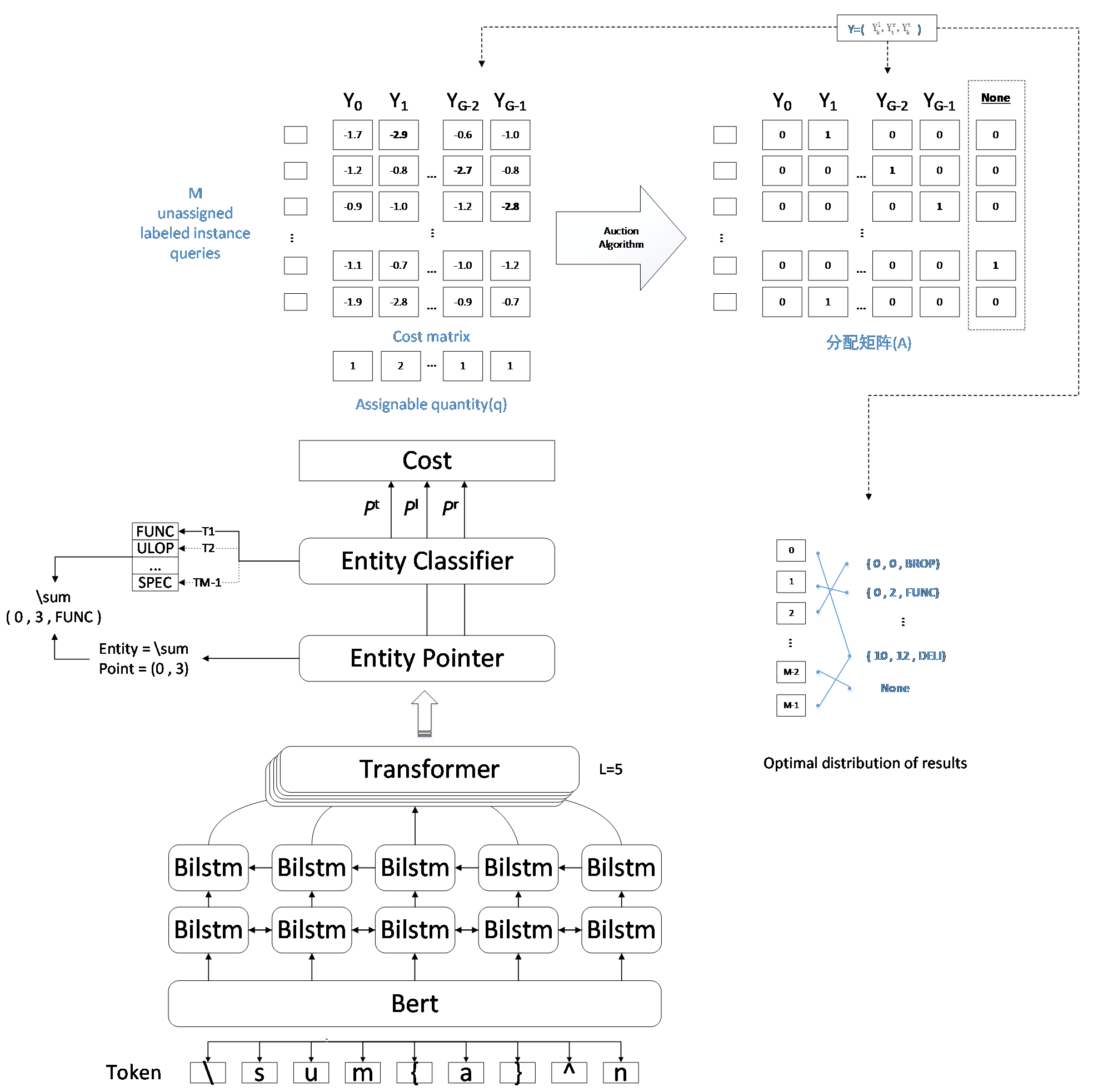
Based on the similarities between sequences of mathematical formulas and textual information, in everyday use mathematical formulas are often in the form of latex encoding, thus allowing useful features to be learned from the data in a textual form. BERT-formula is a hybrid model architecture based on the BERT model encoding. A vector representation of each character is first computed, spliced with a randomly initialized vector representation of the instance query, and then jointly fed into BERT for encoding, followed by the use of unidirectional Self-Attention, which allows the queries to model connections with each other, enhancing the query semantics [27]. This is followed by feature extraction through BiLSTM layer and transformer layer to improve the model's generalization capacity even more. Finally, a dynamic label assignment mechanism is designed to ascertain the best possible result for the assignment, and label assignment is regarded as a one-to-many Linear Assignment Problem (LAP) (Burkard and Cela, 1999) [28]. The final predicted labelling outcome is obtained by finding the minimum cost matrix of the allocation problem and finding the optimal allocation.
Figure 1 displays the model's framework as suggested in this paper. There are three components to it: encoder, entity prediction and dynamic label assignment, where entity classification and entity localization are the two subtasks of entity prediction. The input of the encoder part comes from textual information as well as instance queries that can learn global semantic information, and the vector representation is obtained by using embedding to extract rich syntactic and semantic elements; the entity prediction part mainly accomplishes the boundary prediction of the entity as well as the category prediction of the entity, and if more than one prediction for the same entity occurs, The one chosen to be kept is the one with the highest probability value; the dynamic label entity assignment mainly According to the allocation cost generated in the previous part to form the Cost matrix, and then further use the algorithm of the linear allocation problem to calculate the label allocation matrix with the minimum cost, so as to achieve the instance query and the allocation of entity labels, and get the prediction results of each entity to complete the recognition task.
To indicate an example of training, we use , where is a sentence with words, and the three represent the index of the left boundary of the -th entity, the index of the right boundary, and the index of the entity type, respectively. In our study, globally learnable instance queries are set up, it extracts an entity from the phrase in each case. During training, they can independently learn query semantics and are initialized at random. Therefore, the challenge involves using the learnable instance inquiry to extract entity from an input sentence .
Two components make up the model's input: an instance query of length M and the text of a latex mathematical formula of length N. The Encoder is responsible for stitching them together into a sequence and encoding them at the same time. The instance query of length M is a randomly generated sequence of a fixed-length segment, which is composed without the aid of external knowledge and learns deep semantic information between sentences.
Firstly, we start with the computation of embedding, with the help of Bert embedding we compute the Token embedding, Position embedding and Type embedding of the sequence, after that we stitch the two embedding information to get the , , .
where denotes the Token embedding of the word sequence, denotes the vector representation of the instance query, and denote the learnable positional embedding of the text sequence and the instance query sequence, and denote the type embedding of the text and the type embedding of the instance query respectively, and denotes the repetition of the -th and -th times.
The further input to the encoder can thus be represented as:
Sentences can communicate with all instance queries thanks to common self-attention. Randomly produced instance queries might so alter the sentence's encoding and ruin its semantics. In order to keep the semantics of the sentence relatively independent from the instance queries, we replace the unidirectional form of self-attention in BERT with a version that maintains the sentence semantics largely independent from the instance queries.
where are the parameters of the weight matrix, is the mask matrix representing the attention scores. The components that are set to 0 are reserved units, whereas the elements that are set to are removed units. The top-right sub-matrix in our approach is a full matrix of size with all other members set to 0. This prevents instance queries from participating in sentence encoding. Furthermore, the self-attention between instance queries can improve their query semantics and model the connections between them.
Following BERT encoding, we use two bidirectional LSTM layers and (experimentally set to 5) extra transformer layers to further encode the phrases at the character level. Finally, we will split into two parts: sentence encoding and instance query encoding .
One entity from a phrase can be predicted by each instance query, and a maximum of M entities can be predicted concurrently with M instance inquiries. One way to think of entity prediction is as a combination of boundary and category prediction. We have designed entity pointers and entity classifiers from different perspectives.
Firstly, we use two linear layers to interact with each character in the phrase for the -th instance query . The fused representation of the -th instance query and the -th character can be computed as:
where represents the left and right boundaries, are trainable projection parameters. Next, we determine the possibility that the sentence's -th word represents a left or right boundary.
where and are learnable parameters.
Information about entity boundaries is helpful for classifying entities. We use , to evaluate each word and relate it to the instance query. It is possible to calculate the boundary-aware representation of the -th instance query as:
where is a learnable parameter. The probability that the entity that the -th instance query is attempting to query falls into category can then be obtained:
where and are learnable parameters.
Finally, the entity predicted by the -th instance query is . , is the left and right boundaries, and is the entity type.
We extract entities in parallel by performing entity classification and entity localization for every instance query. If multiple instance queries predict different types when locating the same entity, then we keep the one with the highest classification probability as the prediction.
Since instance queries are implicit (not in natural language form), we are unable to assign optimal entities to them in advance. In order to address this issue, we are going to assign labels to instance queries during training dynamically. Label assignment is specifically thought of as a linear assignment problem. Any entity can be assigned to any instance query, and the cost incurred may vary due to instance query assignment. We define the cost of assigning the kth entity () to the ith instance query as:
where indicates the entity type of the -th entity, the index of the left boundary and the right boundary. In order to allocate as many entities as possible, A maximum of one entity per query and a maximum of one query per entity must be allocated, which ensures that the total cost of allocation is minimized. Nevertheless, Numerous instance queries are not allocated to the best possible entities, and the one-to-one rule fully utilizes instance queries. In order to enable one entity to be assigned to more than one instance query, we therefore extend the traditional LAP (Linear Assignment Problem) to one-to-many. The optimization objective of this one-to-many LAP is explained as:
where is the matrix of allocation, indicates the number of entities, denotes the -th entity allocated to the -th instance query. indicates the assignable quantity of the -th entity, represents all entities' total assignable quantity. The assignable numbers of each entity type are balanced in our experiments.
Then we used the Auction Algorithm to settle the entity allocation problem by generating the label allocation matrix with the lowest possible overall cost. However, there are more instance inquiries than there are entity labels available for allocation . Consequently, certain instance queries won't be assigned to any entity label. We expand the allocation matrix by one column and assign them "None" labels. The vector a of the new column is set up as follows:
On account of new allocation matrix , we are able to obtain the labels of instance queries , where is the index vector of labels of instance queries in the optimal allocation case.
After the above steps, we as well compute the entity prediction results for M instance queries and get their labels when the total allocation cost is minimum. We specify the classification loss and boundary loss for training model. We utilize the binary cross entropy function to get the loss values for left and right border prediction:
We employ the cross entropy function for entity categorization to calculate the loss value:
where represents an indicator function that takes 1 when true and 0 otherwise.
Following Al-Rfou et al. [29] and Carion et al. [30], after every character level transformer layer, we add an entity pointer and an entity classifier, allowing us to obtain two loss values at each layer. As a result, the overall loss on training set can be described as:
where , are the classification loss and boundary loss of the layer, respectively. In order to predict, we solely use entity prediction at the last layer for prediction.
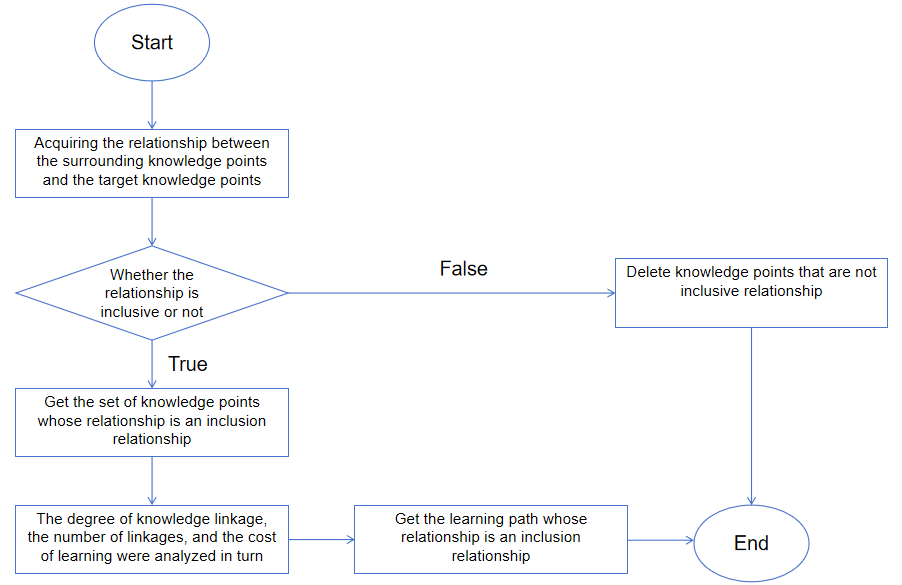
Knowledge graphs (KGs) serve as a pedagogical and computational scaffold for structuring fragmented knowledge domains, enabling the generation of logically coherent learning paths that respect intrinsic educational dependencies such as prerequisite sequences, hierarchical inclusions, and conceptual analogies. Unlike traditional methods, which often prioritize isolated content delivery, KGs formalize knowledge topology through nodes (e.g., "Gradient Descent") and edges (e.g., "is_prerequisite_for"), allowing systematic traversal from a target node (e.g., "Convolutional Neural Networks") to prerequisite foundations (e.g., "Linear Algebra" or "Image Processing"). This structural rigor ensures learning continuity by mandating that no critical intermediate concepts are omitted, thereby preserving the integrity of pedagogical logic. For instance, omitting "Backpropagation" in a path toward "Deep Reinforcement Learning" would violate prerequisite dependencies, undermining learning efficacy. To operationalize this, a hybrid recommendation strategy is proposed, integrating inclusion-relation prioritization and multi-criteria node ranking. First, inclusion relations (e.g., "Machine Learning Fundamentals" "Supervised Learning") are extracted using subgraph isolation:
where denotes the subgraph of nodes directly containing or contained by the target node . Subsequently, candidate nodes are ranked by a composite metric balancing association strength and learning cost. Association strength is quantified via a weighted combination of inverse shortest-path distance and node centrality ;
where and calibrated through learner feedback or A/B testing. Nodes with higher scores are prioritized, while ties are resolved using learning cost , modeled as a function of historical learner engagement () and resource complexity :
where adjusts the weight of temporal versus cognitive load. This framework aligns with graph-based recommendation paradigms such as Zhang et al. [31] graph convolutional network (GCN) approach, which leverages node embeddings to capture latent educational dependencies, and Zheng et al. [32] ant colony optimization variant, dynamically balancing exploration of novel concepts and exploitation of known pathways. Furthermore, Shi et al. [33] validate the necessity of multidimensional KGs, demonstrating that integrating node centrality (e.g., PageRank scores) and learner-specific factors (e.g., proficiency levels) enhances path personalization for learners, as measured by retention metrics. The methodology's robustness is further reinforced by its compatibility with ontology-enriched KGs, where named entity recognition (NER) refines node categorization—for example, distinguishing "Bayesian Inference" as a theoretical versus applied concept—ensuring granular alignment with curricular taxonomies [34]. Figure 2 shows the general process of learning path recommendation based on knowledge graph.
In this paper, we use manual annotation to extract more than four thousand latex mathematical formulas from the text of about 100,000 words of operations research textbook, which contains more than 10,000 entities and annotate the latex formulas, and there are five types of entity categories defined, namely: Function operator, Unary logical operator, Binary relation operator, Delimiter and Special operator. Table 1 shows certain entities' pertinent descriptions and examples.
| Type of entity | Notation | Description | Example |
|---|---|---|---|
| Function operator | FUNC | Minimum, maximum | \min, \max, … |
| Unary logical operator | ULOP | Include, less than, more than… | \in, \leq, \geq, … |
| Binary relation operator | BROP | Intersection, union … | \land, \vee, … |
| Delimiter | DELI | Array… | \begin{pmatrix}, … |
| Special operator | SPEC | Root sign, fraction | \sqrt, \frac, … |
In the named entity recognition task, there are two commonly used annotation approaches, which are BIO annotation method and BIOES annotation method. In the BIO annotation approach, B-begin denotes the entity's first character, I-inside its middle character, and O-outside its character that is unrelated to any of the other entities. (which can be interpreted as the character that doesn't exist in any entity). When using the BIOES annotation method, the B stands for the entity's beginning, the I for its middle, the O for the character unrelated to the entity, the E-end for its end, and the S-single for the single character, which is an entity in and of itself. This article uses the BIO annotation method.
Three indicators—precision (P), recall (R), and F1 value (F1)—are used in this research as the criteria for assessing the model's efficacy. P is how many true positive samples are there in the samples predicted to be positive; and R is how many positive samples are predicted correctly with respect to the original positive samples. When we use these two metrics to judge the merits of a model, one would often hope that the values of both precision and recall are at a high level, but in practice this is often not the case because the two metrics are contradictory in some cases. In order to give a more comprehensive judgment of the model, the reconciled average of precision and recall, F1, is introduced. P, R and F1 are calculated as follows:
where is the number of entities that the model properly identified, is the number of unrelated entities that the model identified, and indicates the quantity of related entities that the model failed to recognize.
The experiments are based on the torch framework to build neural network models, and the detailed configuration of the experimental environment is shown in Table 2.
| Environment | Configuration | ||
| Hardware | OS | Windows 11 | |
| CPU |
|
||
| GPU | GeForce RTX 3060 | ||
| Memory | 32 GB | ||
| Software | Python | Python 3.6 | |
| Pytorch | torch 1.9.1 | ||
The main training parameters involved in the experiment are shown in Table 3. The quantity of Transformer layers used for the BERT model is 12, hidden layer dimension 768, number of head 12, optimizer AdamW, learning rate 0.00002, Lstm_dim 384, Batch_size 4, dropout 0.4, gradient_clip 1, weight_decay 0.1, max_len 512, epochs 50.
| Environment | Configuration |
|---|---|
| Transformer | 12 |
| Hidden_size | 768 |
| Number of head | 12 |
| Optimizer | AdamW |
| Learning_rate | 0.00002 |
| Lstm_size | 384 |
| Drop_out | 0.4 |
| Gradient_clip | 1 |
| Weight_decay | 0.1 |
| Batch_size | 4 |
To confirm the capability of the proposed model (BERT-formula) for entity recognition of mathematical formulas in operations research, it was compared with four models, BiLSTM, BiLSTM-CRF and Bert-BiLSTM-CRF, in the same experimental environment in terms of three indexes: accuracy, recall, and F1 value. The results of the experiments are shown in Table 4.
| Methods | Accuracy | Recall | F1 |
|---|---|---|---|
| BiLSTM | 36.93 | 37.60 | 37.26 |
| BiLSTM-CRF | 70.41 | 74.86 | 72.57 |
| BERT-BiLSTM-CRF | 97.37 | 98.28 | 97.82 |
| Ours | 98.88 | 98.88 | 98.87 |
From Table 4, it is evident for us to test the effect of each model for the entity recognition of operational research formulas. It can be seen that the capability of BiLSTM alone is very limited, while after combining with CRF, The model's recognition impact has significantly improved. The BERT-BiLSTM-CRF model has a large improvement in the recognition effect due to the fact that BERT has the capability of extracting local and contextual features, which produces feature vectors with a more accurate representation.
This research investigates named entity recognition of mathematical formulas based on text in the field of operations research, and proposes a model for named entity recognition of mathematical formulas, BERT-formula. an efficient feature representation of mathematical formulas using embedding is spliced with a vector representation of randomly initialized instance queries, which are then jointly input to BERT for encoding, and then encoded using one-way Self-Attention, which allows the queries to model connections with each other and enhances the query semantics. After that, feature extraction is performed through BiLSTM layer and transformer layer, and finally the final predicted labeling results are obtained by finding the optimal allocation by finding the minimum cost matrix for the allocation problem. The experimental findings demonstrate that, in comparison to the conventional NER technique, the inference speed of the approach presented in this study is significantly enhanced, and it is also superior in terms of recognition results. The identified formula entities can further support adaptive learning path recommendations by mapping domain-specific knowledge components to targeted educational resources. The named entity recognition of operations research formulas achieved in this research establishes a strong basis for downstream NLP tasks in the field of operations research, and the example queries in this paper do not rely on external knowledge, but throughout the training phase, acquire the query semantics associated with the entity type and location, which saves a lot of manual consumption; the feature of not relying on the knowledge related to a specific domain also makes the method can be easily applied to other domains. At the same time, for the problem of fewer datasets of text labeling of mathematical formulas in the field of operations research, a dataset of operations research latex formulas is constructed, which contains nearly five thousand data, and it is anticipated that it will contribute in some way to the advancement of operations research. Subsequently, the size of the dataset will be further expanded to further verify the transferability of the model and apply the model to other fields.
 Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Frontiers in Educational Innovation and Research
ISSN: request pending (Online)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/