
IECE Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3066-1676 (Online) | ISSN: 3066-1668 (Print)
Email: [email protected]

In the field of computer vision, object detection is a key task that involves identifying and locating single or multiple objects in an image. This technology has a wide range of application scenarios, including but not limited to autonomous driving, video surveillance, human-computer interaction, and industrial automation. Especially in the fields of autonomous driving and safety monitoring, object detection plays a crucial role. For example, in autonomous driving systems, accurate target detection can not only identify vehicles, pedestrians, and obstacles on the road but also interpret traffic signs and signals to ensure driving safety. In the field of video surveillance, target detection [1, 2] can help the surveillance system effectively identify and track specific targets, which is crucial for improving public safety and preventing criminal activities.
Before deep learning became popular, object detection mainly relied on hand-designed features and traditional machine learning techniques. A common method is to use sliding window technology with feature descriptors such as SIFT (Scale Invariant Feature Transform) [3], SURF (Speed-up Robust Features) [4] or HOG (Histogram of Oriented Gradients) [5]. Sliding window technology moves windows of different sizes on the image, extracts features on each window, and then uses a classifier such as SVM (Support Vector Machine) [6] to identify and classify targets.
For example, the HOG feature proposed by Dalal and Triggs in 2005 combined with linear SVM was one of the early benchmark methods for pedestrian detection. The HOG feature captures the shape information of the target by calculating the gradient direction histogram of the local area of the image, which is effective for single-scale pedestrian detection. However, when the target size is variable or the background is complex, the effect of this method will drop significantly, because hand-designed features often lack adaptability to complex changes. Although object detection technology has made significant progress, it still faces several challenges. Traditional target detection methods work well in simple scenes but often perform poorly in complex environments.
In the field of target detection, existing deep learning methods for dealing with multi-scale and variability problems mainly focus on improving the network architecture to adapt to targets of different scales. Feature Pyramid Network (FPN) [20] is an effective solution. It achieves the fusion of high-level semantic information and low-level detailed information by establishing a top-down information flow and generating feature maps at different levels. In this way, the feature maps at each level can correspond to targets of different sizes, greatly improving the detection ability of small targets. In addition, the deformable convolutional network (DCN) [23] introduces learnable offsets to enable the convolution kernel to adapt to the specific shape and posture of the target, enhancing the network's adaptability to complex shape and posture changes. The application of these technologies significantly improves the model's performance in multi-scale and high-variability environments, while also maintaining a high recognition rate for large-sized targets. These advances not only solve the problems encountered by traditional methods in complex scenes but also promote the development of target detection technology in a more efficient and accurate direction.
However, these existing deep learning methods still have shortcomings in handling multi-scale and variability objects. On the one hand, traditional convolutional networks are usually sensitive to the size of the input image, and their performance is often affected when encountering targets with large size changes. On the other hand, complex background and environmental factors (such as lighting changes, occlusions, and background clutter) can also reduce detection accuracy. Therefore, developing a target detection algorithm that can adapt to multi-scale changes and have high environmental adaptability has become a research hotspot.
This paper proposes an improved target detection algorithm based on multi-scale and variability convolutional neural networks. The algorithm is specially designed with a multi-scale feature fusion mechanism that can effectively integrate information from different convolutional layers, thereby improving the detection capabilities of small and large-sized targets. At the same time, we introduced a variable convolution structure, which dynamically adjusts the convolution kernel parameters to cope with different detection scenarios and enhances the model's adaptability to complex environments.
To verify the effectiveness of the proposed algorithm, we conduct extensive experiments on three public datasets, KITTI [8], NEXET and Caltech [14]. The KITTI dataset is widely used for visual tasks related to autonomous driving, and contains vehicle and pedestrian detection data in a variety of traffic scenarios; while the Caltech dataset focuses on pedestrian detection, covering various pedestrian sizes and complex background conditions. Through testing on these two data sets, we not only demonstrated the efficient performance of the algorithm in general target detection tasks but also specifically verified its superiority in multi-scale and high-variation environments.
Our contributions mainly include:
Developed a new multi-scale feature fusion strategy, which significantly improves the detection accuracy of targets of various sizes by precisely controlling the integration of information flow between different scales.
Designed a variable convolution module that uses a learnable parameter adjustment strategy to enable the network to automatically adjust its feature extraction method according to the characteristics of the target and environmental conditions.
Comprehensive experiments are conducted on KITTI and Caltech datasets, and the results demonstrate that our model has significant performance advantages over existing technologies when handling target detection tasks in multi-scale and complex environments.
Through these innovations, our algorithm not only performs well on standard data sets but also demonstrates its wide applicability and practical value in practical application scenarios, providing new technical solutions for target detection in complex environments.
In the field of target detection, with the continuous advancement of technology, researchers have developed a variety of complex methods to deal with various challenges, especially for the detection of multi-scale and deformed targets. These methods are not only innovative in theory, but also show extremely high efficiency and accuracy in practical applications. Below is a detailed extended introduction to these methods, divided into three main categories: region-based methods, regression-based methods, and structural optimization/enhancement methods.
R-CNN [11] extracts deep feature representations by applying high-capacity convolutional neural networks to each independent candidate region. Although this method is effective, it is computationally expensive and slow. Fast R-CNN [10] improves this process and introduces a RoI pooling layer, which can quickly extract the features of each region from a unified feature map of the entire image, significantly improving the speed and efficiency while passing Using softmax instead of SVM simplifies the training process. Faster R-CNN [30] further optimizes the generation process of candidate regions by integrating a Region Proposal Network (RPN), which can be jointly trained with the detection network end-to-end, further improving speed and accuracy. Mask R-CNN [13]: Based on Faster R-CNN, a branch is added to generate a pixel-level mask of the target, which enables the model to not only perform target detection but also perform more refined instance segmentation. This method is particularly suitable for application scenarios that require precise target contour information, such as medical image analysis and video editing.
The regression-based method handles target detection in a more intuitive and fast way, directly predicting the location and category of the target on the entire image, greatly improving the processing speed.
YOLO [29] series: Especially YOLOv1 to YOLOv4, each generation has made significant improvements based on the previous generation, such as deeper networks, better feature utilization strategies, and more efficient framework design. YOLO transforms the target detection problem into a single regression problem, achieving very fast detection speed, and is very suitable for occasions that require real-time processing. SSD [24]: This algorithm effectively handles the multi-scale target detection problem by predicting the location and category of the target on multiple feature maps of different scales. The design of the SSD allows it to achieve very good speed performance while maintaining high accuracy. EfficientDet [32]: This algorithm further balances the depth, width, and input image resolution of the network through compound scaling technology, improving efficiency and accuracy. EfficientDet shows excellent performance on multiple standard datasets, especially on resource-constrained devices.
In order to adapt to changes in multi-scale and target morphology, some methods improve the adaptability and accuracy of the model through structural optimization.
Feature Pyramid Network (FPN): By establishing multi-level feature maps, each layer can extract information at different scales. FPN can effectively enhance the model's detection capabilities for targets of various sizes. This top-down structure provides rich semantic information and detailed information for target detection. Deformable Convolutional Networks (DCN): By allowing the shape of the convolution kernel to dynamically adapt to the characteristics of the input data, DCN provides the possibility to handle irregularly shaped targets, which is difficult to achieve in traditional convolutional networks. RetinaNet [21]: By introducing Focal Loss, it solves the imbalance problem of positive and negative samples often encountered in target detection, especially when there are a large number of easy-to-classify background samples, and improves the detection performance of small targets.
Each of the above methods has its own merits, but what they have in common is that they have greatly promoted the development of target detection technology, improved the accuracy, speed, and adaptability of detection, and met the needs of different platforms from mobile devices to high-performance servers.
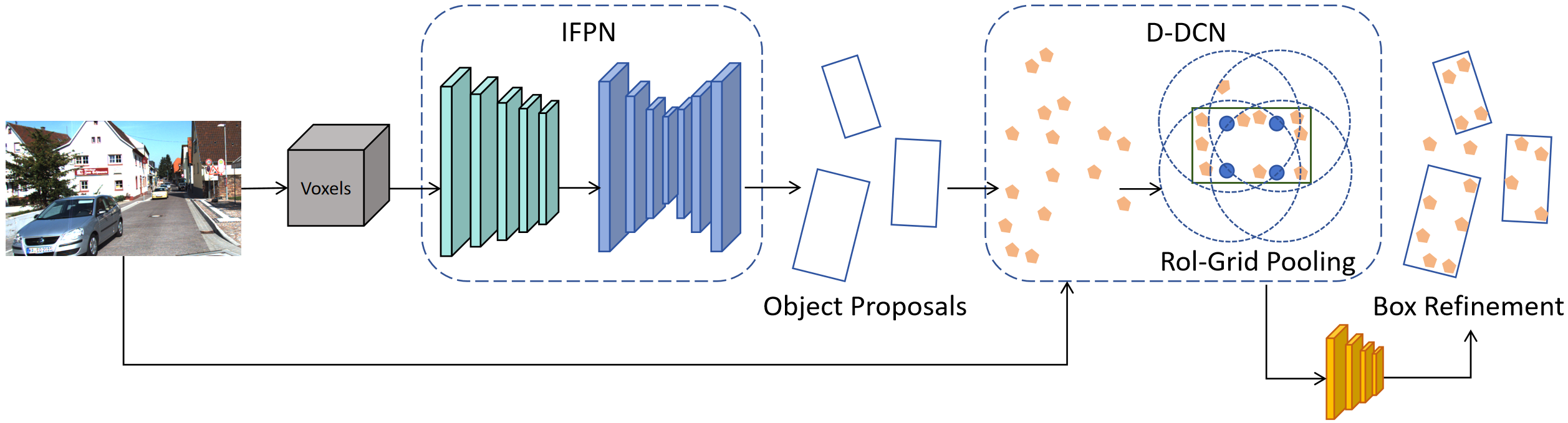
To effectively address the challenges of multi-scale and high variability, our research work introduces two innovative techniques: improved feature pyramid network (iFPN) and dynamically deformable convolutional network (D-DCN). These methods effectively address critical challenges related to size adaptation and shape variation in target detection. By employing precise mathematical formulations and sophisticated network designs, they substantially enhance the performance and adaptability of the detection algorithm. The overall architecture of our network is presented in Figure 1, and the process is detailed in Algorithm 1.
Input: Feature Map , Weights , , Parameters , , ,
Output: Detection Results
Initialize weights and parameters , , , ;
for each feature map in do
Compute semantic score: ;
Compute adaptive weight: ;
end for
Compute merged feature: ;
for each position in do
Compute position offset: ;
Compute shape offset: ;
for each kernel position in do
Adjusted position: ;
Adjusted kernel: ;
Convolution output: ;
end for
end for
return Detection Results
In order to further improve the effect of multi-scale target detection, we developed the improved feature pyramid network(IFPN), which is a network architecture specially designed to improve the efficiency and quality of information fusion between feature layers. IFPN not only comprehensively utilizes features from different layers, but also introduces a novel adaptive weight adjustment mechanism, allowing the network to automatically adjust its contribution to the final detection task based on the importance of each layer's features.
Semantic Score Assessment: The core of IFPN lies in the semantic evaluation of each feature layer, which determines the weight of this layer in feature fusion. The semantic evaluation is based on the assumption that deeper networks usually capture higher-level semantic information, which is especially important for recognizing small-sized objects. We analyze the output of each feature layer through a deep convolutional network and calculate its semantic score. The process can be expressed as:
where is the feature map Conv of the -th layer, represents the convolution operation and are the weight and bias of the convolution layer respectively, and is usually a nonlinear activation function, such as ReLU [12] or Sigmoid, to ensure the output The score is within a reasonable range.
Dynamic Weight Adjustment: Based on the semantic score of each layer, we calculate dynamic weights to adjust the influence of each layer's features in the fusion process. This dynamic adjustment mechanism allows the network to automatically optimize the feature fusion strategy based on different inputs, thereby better-handling targets of various sizes. This process can be expressed as:
where is a trainable scaling parameter used to adjust the sensitivity of the softmax function, thereby affecting the weight distribution of different feature layers.
Feature Fusion Strategy: Using the calculated weights, we perform a weighted fusion of features from all layers to generate the final feature map for object detection. This step is accomplished through upsampling and weighted summation, ensuring that all feature maps contribute to the final detection result. The fusion process is:
where is an upsampling operation, which upsamples each feature map to a uniform size for effective fusion.
Through this improved feature pyramid network design, iFPN can more effectively utilize features from different network depths and optimize the detection capabilities of multi-scale targets. This not only enhances the model's sensitivity to small-sized targets but also improves its ability to adapt to changes in background complexity. In addition, the adaptive characteristics of IFPN enable it to automatically adjust the feature fusion strategy according to specific tasks and data sets, further improving the versatility and flexibility of the model. These properties make IFPN a powerful tool for multi-scale object detection scenarios ranging from simple to extremely complex.
In object detection, a dynamically deformable convolutional network (D-DCN) is a novel technology designed to solve the problem of irregular shape and pose changes of objects. Traditional fixed convolution kernels perform poorly in handling such changes because they cannot adapt to the local structure and shape changes of the target. In order to solve this problem, D-DCN introduces a dynamic deformation mechanism that enables the convolution kernel to adjust dynamically according to the specific shape of the target, thereby more accurately capturing the detailed information of the target.
Dynamic Offset Calculation: In dynamically deformable convolutional networks (D-DCN), the calculation of dynamic offsets is one of the key steps. These offsets allow the convolution kernel to adjust dynamically according to the local structure and shape changes of the target to more accurately capture the detailed information of the target. We will introduce the calculation process of position offset and shape offset respectively.
Position Offset Calculation: The position offset is used to adjust the position of the convolution kernel to adapt to the position change of the target. This process utilizes a convolutional layer and a nonlinear function to generate position offsets. Expressed in the following form:
where represents the position offset, is the learnable parameter Conv represents the convolution operation, and is the input feature map is the weight of the convolution layer. Through this formula, the network can learn the position offsets at different positions based on the input feature map .
Shape Offset Calculation: Shape offset is used to adjust the shape of the convolution kernel to adapt to changes in the shape of the target. This process also uses a convolutional layer and a nonlinear function to generate shape offsets. The process can be expressed as follows:
where represents the shape offset, is the learnable parameter, is a nonlinear activation function, Conv represents the convolution operation, is the input feature map, and is the weight of the convolution layer. Through this formula, the network can learn the shape offsets at different positions based on the input feature map .
Through the calculated position offset and shape offset, D-DCN can dynamically adjust the position and shape of the convolution kernel during the convolution operation, thereby better capturing the local structure and shape changes of the target.
The dynamic convolution operation in the dynamically deformable convolutional network (D-DCN) is one of its core components. It enables the network to dynamically adjust the position and shape of the convolution kernel according to the local structure and shape changes of the target, thereby making it more precise. Capture the characteristics of the target well.
Generation of Dynamic Convolution Kernel: In dynamically deformable convolutional networks (D-DCN), the generation of dynamic convolutional kernels is a key task. In traditional convolution operations, the weight of the convolution kernel is fixed, but in D-DCN, the weight of the convolution kernel is adjusted according to the dynamic offset to adapt to the irregular shape and attitude changes of the target.
Offset-based Dynamic Convolution Kernel:The generation of dynamic convolution kernel is based on the adjustment of offset. During the convolution process, for each convolution kernel position p, it is adjusted according to the learned offset to adapt to the local structure and shape changes of the target. Specifically, the weight of the dynamic convolution kernel can be calculated by the following formula:
where is the position index of the convolution kernel, and and are learnable parameters, which are used to control the dynamic adjustment of the convolution kernel weight. Conv represents a convolution operation. Through the learned parameters and input feature maps, dynamically adjusted convolution kernel weights can be generated.
Dynamic convolution kernel has the following advantages: 1) Strong adaptability: The weight of the convolution kernel is adjusted according to the learned offset so that the network can better adapt to the irregular shape and posture changes of the target. 2) High flexibility: The weight of the convolution kernel can be dynamically adjusted according to the specific conditions of the target, to better capture the characteristic information of the target.
Through the generation of dynamic convolution kernels, the D-DCN network can better adapt to targets of various shapes and postures, thereby improving the accuracy and robustness of target detection. The calculation process of dynamic convolution operation includes the following steps: 1) Position adjustment of the convolution kernel: For each convolution kernel position , the position of the convolution kernel is dynamically adjusted according to the learned offset . 2) Convolution kernel weight adjustment: Calculate the dynamically adjusted convolution kernel weight based on the adjusted convolution kernel position and shape. 3) Calculation of convolution output: For each convolution kernel position , use the dynamically adjusted convolution kernel weight to perform a weighted sum to obtain the convolution output value . The process can be described as:
Through this operation, the D-DCN network can dynamically adjust the position and weight of the convolution kernel according to the local structure and shape changes of the target, thereby better adapting to the characteristics of the target.
When designing the loss function, we hope that it can accurately reflect the difference between the model predictions and the real labels and that it can effectively guide the training process of the model. In target detection tasks, we usually need to consider two aspects of error: positioning error and category classification error.
Position Positioning Error loss function: The location error loss function measures the difference between the model's prediction of the target location and the true location. The commonly used positioning error loss function is Smooth L1 Loss, which is a variant of Huber Loss. It uses square loss for smaller errors and absolute value loss for larger errors to reduce the impact of outliers on training. This loss is expressed as:
where is the target position parameter predicted by the model, is the real target position parameter, and SmoothL1(x) is the Smooth L1 Loss function.
Classification Error loss function. The classification error loss function measures the difference between the model's prediction of the target class and the true class. A commonly used classification error loss function is the cross-entropy loss function, which imposes a greater penalty on incorrect classification predictions, thereby prompting the model to learn more accurate classifications. The loss function can be expressed as:
where is the target category probability distribution predicted by the model, is the true target category label, and is the predicted probability corresponding to the true category label.
Comprehensive loss function design: To comprehensively consider positioning error and classification error, we can adopt the form of a joint loss function when designing the loss function, taking into account the errors in these two aspects at the same time. A common approach is to perform a weighted sum of the positioning error loss function and the classification error loss function to obtain a comprehensive loss function:
where is the trade-off parameter between positioning error and classification error, which is used to balance the importance of the two in the training process. By designing an appropriate loss function, we can effectively guide the training of the model and improve the performance of the target detection task.
For a fair comparison, all models were trained on a server equipped with four NVIDIA A30 GPUs. We apply the Adam [18] optimizer with a learning rate of 0.001. Batch Normalization [16] is used following each parameter layer. A weight decay of 0.0001 is used in both networks. Refer to Table 1 and Table 2 for a comprehensive list of the parameters.
| Parameter | Configuration |
|---|---|
| CPU | Intel Core i9-12700KF |
| GPU | NVIDIA GeForce RTX A30 (24 GB) |
| CUDA | CUDA 11.7 |
| Python | Python 3.9.13 |
| Deep learning framework | Pytorch 2.1.0 |
| Operating system | Ubuntu 22.04.2 |
| Parameter | Value |
|---|---|
| lr | 0.0002 |
| Optimizer | Adam |
| Batch Size | 24 |
| Weight Decay | 0.0003 |
| Epoch | 350 |
| Activation Function | ReLU |
| Early Stop | True |
| Model | Time | Cars | Pedestrians | Cyclists | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||
| LSVM-MDPM-sv [9] | 10s | 68.02 | 56.48 | 44.18 | 47.74 | 39.36 | 35.95 | 35.04 | 27.50 | 26.21 |
| DPM-VOC-VP [28] | 8s | 74.95 | 64.71 | 48.76 | 59.48 | 44.86 | 40.37 | 42.43 | 31.08 | 28.23 |
| SubCat [26] | 0.7s | 84.14 | 75.46 | 59.71 | 54.67 | 42.34 | 37.95 | - | - | - |
| 3DVP [35] | 40s | 87.46 | 75.77 | 65.38 | - | - | - | - | - | - |
| AOG [19] | 3s | 84.80 | 75.94 | 60.70 | - | - | - | - | - | - |
| Faster-RCNN | 2s | 86.71 | 81.84 | 71.12 | 78.86 | 65.90 | 61.18 | 72.26 | 63.35 | 55.90 |
| CompACT-Deep [37] | 1s | - | - | - | 70.69 | 58.74 | 52.71 | - | - | - |
| DeepParts [33] | 1s | - | - | - | 70.49 | 58.67 | 52.78 | - | - | - |
| FilteredICF [38] | 2s | - | - | - | 67.65 | 56.75 | 51.12 | - | - | - |
| pAUCEnsT [27] | 60s | - | - | - | 65.26 | 54.49 | 48.60 | 51.62 | 38.03 | 33.38 |
| Regionlets [34] | 1s | 84.75 | 76.45 | 59.70 | 73.14 | 61.15 | 55.21 | 70.41 | 58.72 | 51.83 |
| 3DOP [22] | 3s | 90.03 | 88.64 | 76.11 | 81.78 | 67.47 | 64.70 | 78.39 | 68.94 | 61.37 |
| SDP+RPN [36] | 0.4s | 90.14 | 88.85 | 78.38 | 80.09 | 70.16 | 64.82 | 81.37 | 73.74 | 65.31 |
| Ours | 0.4s | 93.04 | 89.02 | 79.10 | 83.92 | 73.70 | 68.31 | 84.06 | 75.46 | 66.07 |


| Model | Times | params | Cars | Pedestrians | ||||
| Easy | Mod | Hard | Easy | Mod | Hard | |||
| 1.5 | 0.12s/0.10s | 471M/217M | 90.55 | 87.93 | 71.90 | 76.01 | 69.53 | 61.57 |
| 2 | 0.43s/0.38s | 471M/217M | 90.96 | 88.83 | 75.19 | 76.33 | 72.71 | 64.31 |
| 3.5 | 0.23s/0.20s | 471M/217M | 94.08 | 89.12 | 75.54 | 77.74 | 72.49 | 64.43 |
| random | 0.22s/0.19s | 471M/217M | 90.94 | 87.50 | 71.27 | 70.69 | 65.91 | 58.28 |
| mixture | 0.22s/0.19s | 471M/217M | 90.33 | 88.12 | 72.90 | 75.09 | 70.49 | 62.43 |
| IFPN | 0.24s/0.20s | 352M/191M | 92.89 | 88.88 | 74.34 | 76.89 | 71.45 | 63.50 |
| D-DCN | 0.22s/0.19s | 344M/138M | 90.49 | 89.13 | 74.85 | 76.82 | 72.13 | 64.14 |
| Ours | 0.19s/0.18s | 103M/82M | 82.73 | 73.49 | 63.22 | 64.03 | 60.54 | 55.07 |
KITTI dataset: The KITTI dataset is one of the most popular datasets for use in mobile robotics and autonomous driving. It consists of hours of traffic scenarios recorded with a variety of sensor modalities, including high-resolution RGB, grayscale stereo cameras, and a 3D laser scanner. Despite its popularity, the dataset itself does not contain ground truth for semantic segmentation. However, various researchers have manually annotated parts of the dataset to fit their necessities.
NEXET dataset: The NEXET dataset, a widely utilized video dataset in autonomous driving research, encompasses data from over 77 countries and more than 1,400 cities. It includes footage captured under three different lighting conditions (day, night, and twilight) and across all four seasons. The dataset also features diverse road types, such as urban, rural, highway, residential, and desert roads, as well as various weather conditions, including clear skies, fog, rain, and snow. With its high-quality video clips and detailed annotations, NEXET serves as an excellent resource for evaluating our method.
Caltech dataset: The Caltech dataset is a widely used dataset for object recognition tasks and contains approximately 9000 images from 101 object categories. The categories were chosen to reflect the variety of objects in the real world, and the images themselves were carefully selected and annotated to provide a challenging benchmark for object recognition algorithms.
We start with an evaluation of the proposal network. Following literature [15], prediction callbacks are used as a performance metric. To be consistent with KITTI's setting, the ground truth is considered recalled if the intersection over union (IoU) ratio of the best matching proposal is higher than 70% for cars and higher than 50% for pedestrians and cyclists. These benchmarks were chosen because, unlike VOC [7] and ImageNet [31], they contain many small objects. Typical image sizes for KITTI and Caltech are 1250x375 and 640x480 respectively. KITTI contains three categories of objects: cars, pedestrians, and cyclists, and three assessment levels: easy, medium, and hard. The "medium" level is the most commonly used. A total of 7,481 images are available for training/validation, and 7,518 for testing. Since no ground truth is available for the test set, we follow the recommendation of [22] and split the training validation set for training and validation. In all reduction experiments, the training set is used for learning and the validation set is used for evaluation. Next, models were trained separately for car detection and pedestrian/bicycle detection. A model for pedestrians was learned on Caltech.
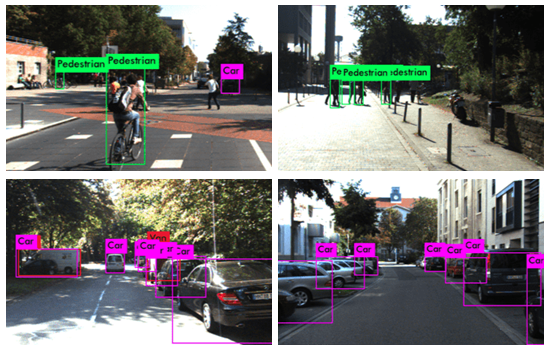
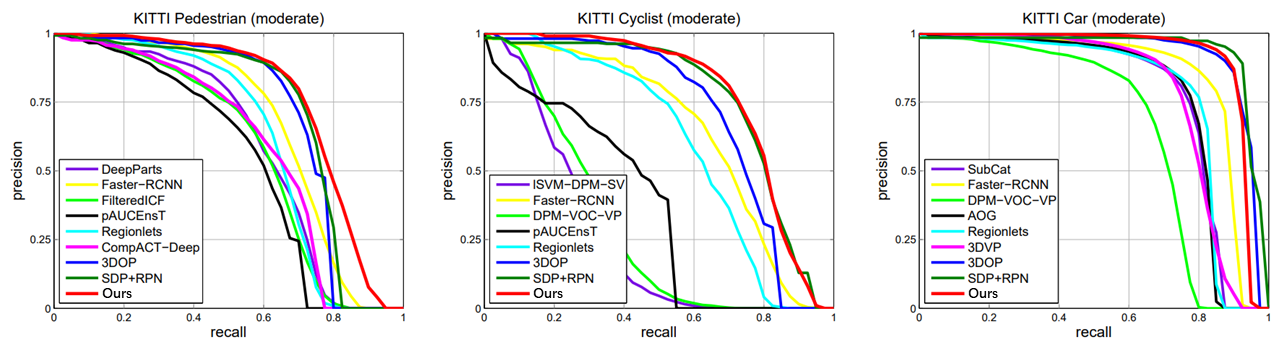
The results on the KITTI: Comparisons with previous methods are shown in Table 3 and Figure 3. We set a new record for detecting pedestrians and cyclists. Columns "Pedestrians-Mod" and "Cyclists-Mod" are 6 and 7 points higher than 3DOP respectively, and perform better than Faster-RCNN, Regionlets, etc. We also achieved considerable lead on the very new SDP+RPN using scale-dependent pooling. In terms of speed, this network is quite fast. For the largest input size, our detector is approximately 8 times faster than 3DOP. On the original image (1250x375), the detection speed reaches 10fps. Figure 2 shows our visualization results.
| Method | Precision | F1 Score | [email protected] | FPS |
|---|---|---|---|---|
| SubCat | 52.36 | 53.59 | 53.58 | 14 |
| 3DVP | 61.95 | 52.47 | 48.33 | 20 |
| AOG | 69.43 | 50.53 | 58.18 | 44 |
| DeepParts | 63.57 | 62.17 | 59.42 | 84 |
| Regionlets | 65.14 | 60.46 | 64.21 | 115 |
| FilteredICF | 69.13 | 65.39 | 67.27 | 99 |
| Ours | 75.07 | 72.37 | 73.67 | 127 |
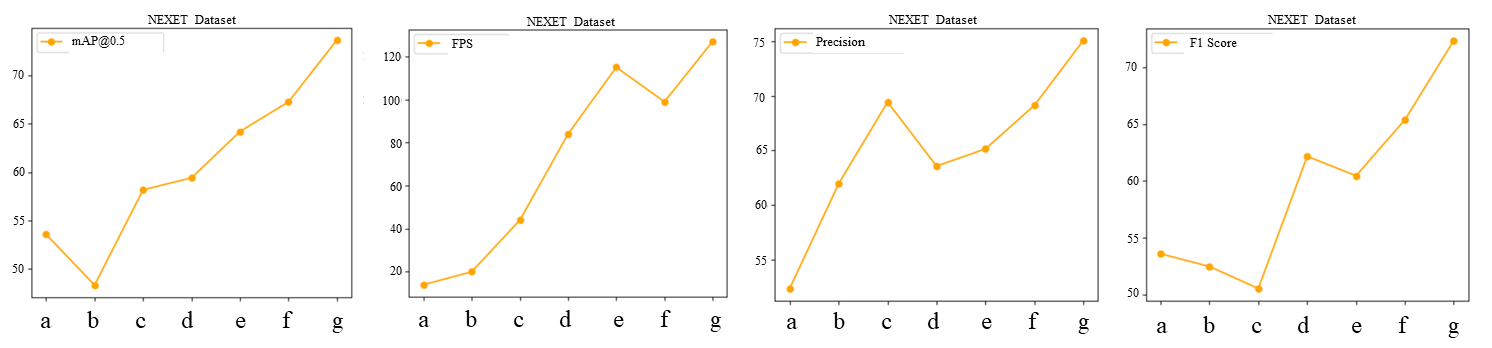
The results on the NEXET: Table 5 offers a thorough comparison of the performance of various methods on the NEXET dataset. Our method stands out with impressive metrics, achieving 75.07% in Precision, 72.37% in F1 Score, 73.67% in [email protected], and operating at 127 FPS. These results underscore the reliability and effectiveness of our approach in different scenarios. Additionally, qualitative outcomes presented in Figures 4 and 5 illustrate that our method performs exceptionally well in real-world applications. In summary, our approach has led to significant advancements in both speed and accuracy.
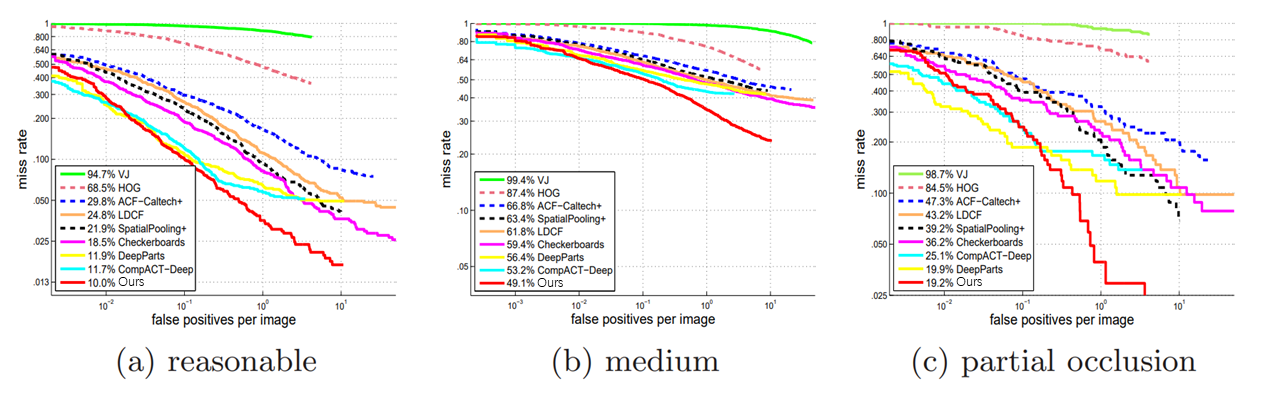
Detection on Caltech: Our detector is also evaluated on the Caltech pedestrian benchmark. The model is compared with methods such as DeepParts, CompACT-Deep, CheckerBoard, LDCF, ACF [25], and SpatialPooling, covering three tasks: Reasonable, medium, and partially obscured. As shown in Figures 6 and 7, our method demonstrates state-of-the-art performance. It performs exceptionally well on small and moving targets objects, surpassing DeepParts, which specifically addresses the occlusion problem.
Effect of input upsampling: Table 4 shows that input upsampling can be a key factor in detection. Significant improvements can be achieved by upsampling the input by a factor of 1.5 to 2, but we found that gains beyond 2x are small. This is smaller than the 3.5x factor required by literature [39]. Larger factors cause detection to be significantly slower and require more memory.
Sampling strategies: Table 4 compares the sampling strategies: random and mixture. For cars, the three strategies are similar; for pedestrians, the bootstrap and hybrid strategies are similar, but the random strategy is significantly worse. Note that random sampling has more false positives.
CNN feature approximation: We tried three methods to learn deconvolution layers for feature map approximation: 1) weights with bilinear interpolation; 2) weights initialized by bilinear interpolation and learned by backpropagation; 3) weights initialized by Gaussian noise and learned by backpropagation. We found that the first method works best, which confirms the research results of [17]. As shown in Table 4, deconvolution layers help in most cases. The gains are greater for smaller input images, which tend to contain smaller objects. It is worth noting that the computational complexity of feature map approximation is very small and does not increase parameters.
Object Detection via Proposal Networks: Proposal networks can act as detectors by converting class-agnostic classification into class-specific classification. Table 4 shows that although not as powerful as the unified network, it achieves quite good results, which are better than some detectors on the KITTI rankings.
This paper proposes an improved object detection algorithm based on Dynamically Deformable Convolutional Networks (D-DCN), which achieves remarkable results through in-depth study of multi-scale and variability challenges in object detection tasks. Our improved algorithm makes full use of the advantages of deep learning technology, innovates in feature extraction and network structure design, and effectively improves the accuracy and robustness of target detection. In the experimental part, we verified it on two commonly used target detection data sets, KITTI and Caltech. The experimental results show that our algorithm achieved significant performance improvement in the target detection task. Compared with traditional methods, our algorithm performs more robustly and accurately across multiple scales and variability. The improved feature pyramid network can effectively extract multi-scale target features, while the dynamically deformable network can achieve accurate detection based on changes in the shape and posture of the target. The comprehensive loss function effectively guides the training process of the model and improves the generalization ability and robustness of the model.
Overall, our work provides an effective method to solve the multi-scale and variability challenges in target detection tasks, with high practical value and prospects for generalization and application. In the future, we will further explore the application of deep learning technology in the field of target detection, continuously improve algorithm performance, and improve the versatility and practicality of the model.
 Copyright © 2024 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2024 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. IECE Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3066-1676 (Online) | ISSN: 3066-1668 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/